














“당신의 반려견이 전 세계를 여행하는 것을 상상할 수 있나? 아니면 파리에서 가장 고급스러운 쇼룸에 진열된 가장 좋아하는 가방을 상상할 수 있나? 삽화가 들어간 동화책의 주인공이 된 앵무새는 어떻습니까?”라는 글의 서문을 읽는다.
이 모델의 핵심 아이디어는 사용자가 원하는 주제 인스턴스의 사실적인 표현을 만들고 텍스트-이미지 확산 모델과 바인딩할 수 있도록 하는 것이다. 따라서 이 도구는 다양한 맥락에서 주제를 종합하는 데 효과적인 것으로 입증되었다.
Google의 DreamBooth는 DALL-E2, Stable Diffusion, Imagen 및 Midjourney와 같이 최근에 출시된 다른 텍스트-이미지 도구와 비교할 때 다소 다른 접근 방식을 취하고 있다. 이는 주제 이미지에 대한 더 많은 제어를 제공하고 텍스트 기반 입력을 사용하여 확산 모델을 안내한다.
DREAMBOOTH 대 세계
기존 모델인 DALL-E2는 주어진 단일 이미지의 의미론적 변형을 합성하고 생성할 수 있지만, 대상의 외양을 재구성하는 데 실패하고 컨텍스트를 수정할 수도 없다. DreamBooth는 주어진 이미지의 주제를 이해하고 이를 이미지의 기존 컨텍스트와 분리한 다음 높은 충실도로 원하는 새로운 컨텍스트로 합성할 수 있다.

개체를 장면에 매끄럽게 혼합하는 작업은 기존 기술이 합성을 위해 하나의 이미지만 업로드할 수 있는 DALL-E2가 있는 텍스트-이미지 전용 모델로 제한되어 있기 때문에 어려운 작업이다. DreamBooth의 AI는 피사체의 입력 이미지를 3~5개만 사용하면 텍스트 프롬프트를 통해 다양한 컨텍스트 내에서 무수히 많은 이미지를 출력할 수 있다.
3D 재구성 도구는 다른 조명의 피사체가 있는 공간을 생성할 수 없다는 유사한 문제가 있다. Google Research의 RawNeRF는 단일 이미지 세트에서 3D 공간을 생성하여 이 문제를 해결했다.
이미지 합성에서 관찰된 또 다른 문제는 생성된 이미지와 관련된 노이즈 맵 및 벡터를 찾는 것과 같은 확산 과정에서 정보가 손실된다는 것이다. Imagen 또는 DALL-E2가 개념을 최적으로 포함하고 표현하여 원하는 출력 이미지의 스타일로 제한하는 동안 DreamBooth는 입력 주제를 고유 식별자. 이는 피사체의 정체성을 유지하고 유지하면서 피사체의 가변적이고 참신한 이미지를 생성하는 결과를 낳는다.
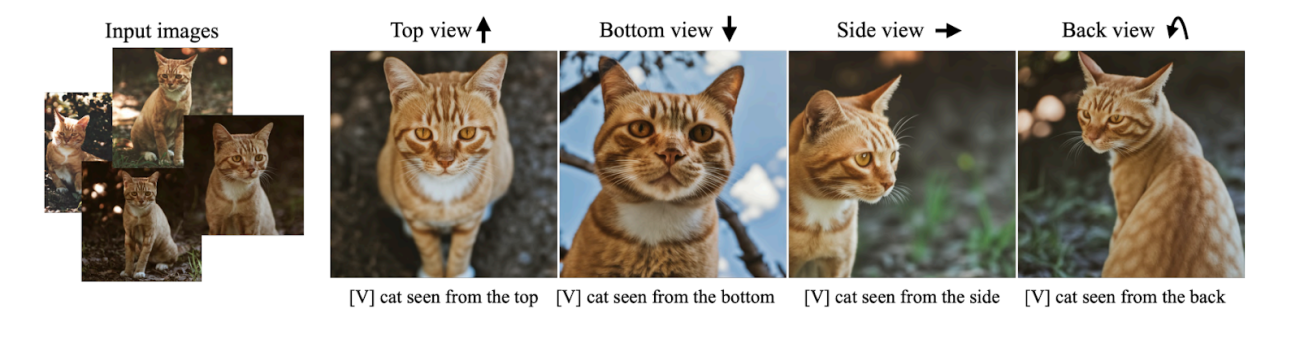
DreamBooth는 또한 몇 가지 입력 이미지의 도움으로 다양한 카메라 시점에서 피사체를 렌더링할 수 있습니다. 입력 이미지에 다양한 각도에서 피사체에 대한 정보가 포함되어 있지 않더라도 AI는 피사체의 속성을 예측하고 텍스트 안내 컨텍스트 내에서 합성할 수 있다.
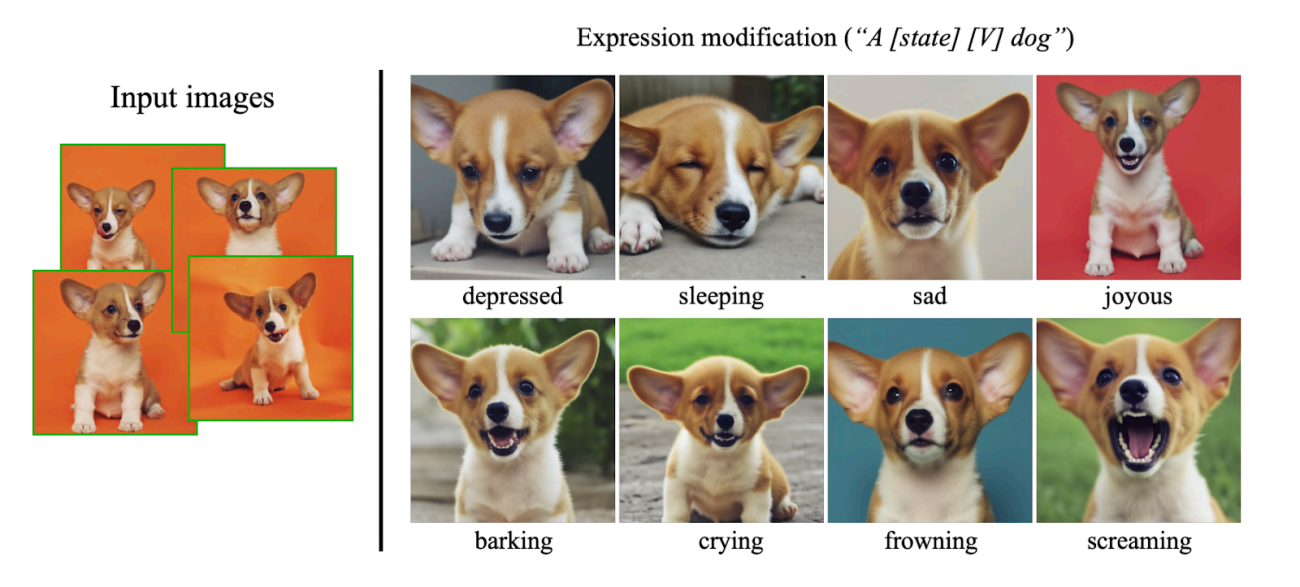
이 모델은 또한 이미지를 합성하여 다양한 감정, 액세서리 또는 색상 수정을 출력할 수 있으며, 텍스트 프롬프트를 통해 사용자에게 더욱 창의적인 자유와 사용자 정의를 허용할 수 있다.
제한 사항
주제에서 세부적인 반복을 생성하려면 명령 프롬프트가 제한됩니다. DreamBooth는 주제의 맥락에서 변형을 만들 수 있지만 주제 내에서 변경하기 위해 모델은 프레임 내 결함에 직면한다.
또 다른 문제는 출력 이미지를 입력 이미지에 과적합하는 것입니다. 입력 이미지의 수가 적은 경우 주제가 평가되지 않거나 주어진 이미지의 컨텍스트와 혼합되는 경우가 있다. 이것은 드문 생성에 대한 컨텍스트를 프롬프트할 때도 발생한다.

일부 다른 제한 사항은 이미지 또는 더 희귀하거나 더 복잡한 주제를 합성할 수 없고 또한 환각적인 변화 및 주제의 불연속적인 특징을 생성하는 주제의 충실도의 가변성이다. 입력 컨텍스트는 종종 입력 이미지의 주제 내에서 혼합된다.
사용자에게 더 많은 권한 제공
대부분의 텍스트-이미지 모델은 수백만 개의 매개변수와 라이브러리를 사용하여 출력을 렌더링하여 단일 텍스트 입력을 기반으로 이미지를 생성한다. DreamBooth는 텍스트 컨텍스트와 함께 피사체의 캡처된 이미지 3~5개만 입력하면 되므로 사용자가 보다 쉽고 액세스할 수 있다. 그런 다음 훈련된 모델은 이미지에서 얻은 피사체의 물질적 특성을 재사용하여 피사체의 고유한 특징을 유지하면서 다양한 설정과 관점에서 이미지를 재현할 수 있다.
대부분의 텍스트-이미지 모델은 특정 키워드에 의존하며 이미지를 렌더링할 때 특정 속성으로 편향될 수 있다. DreamBooth는 사용자에게 새로운 환경이나 컨텍스트 내에서 원하는 주제를 상상하고 사실적인 출력을 생성할 수 있는 선택권을 제공한다.